wpf
excel
RDF三元组
电子学会2022年9月考试
电子电工
模板
遥感数据处理
eureka
Java并发
Pyinstaller
保险
密度泛函理论
三星线刷
定时同步
汇编大作业设计
Sonar
学生选课系统
vuex
推荐计划
摄像头
DiT
2025/1/31 14:41:44![[EAI-027] RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation](https://i-blog.csdnimg.cn/direct/ac2f27c5c0e7474e918e6b75723a1ac2.png)
[EAI-027] RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation
Paper Card 论文标题:RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation 论文作者:Songming Liu, Lingxuan Wu, Bangguo Li, Hengkai Tan, Huayu Chen, Zhengyi Wang, Ke Xu, Hang Su, Jun Zhu 论文链接:https://arxiv.org/ab…

OpenAI视频生成模型Sora的全面解析:从扩散Transformer到ViViT、DiT、NaViT、VideoPoet
前言
真没想到,距离视频生成上一轮的集中爆发(详见《视频生成发展史:从Gen2、Emu Video到PixelDance、SVD、Pika 1.0、W.A.L.T》)才过去三个月,没想OpenAI一出手,该领域又直接变天了
自打2.16日OpenAI发布sora以来,不…

Diffusion Transformer(DiT)——将扩散过程中的U-Net换成ViT:近频繁用于视频生成与机器人动作预测(含清华PAD详解)
前言
本文最开始属于此文《视频生成Sora的全面解析:从AI绘画、ViT到ViViT、TECO、DiT、VDT、NaViT等》
但考虑到DiT除了广泛应用于视频生成领域中,在机器人动作预测也被运用的越来越多,加之DiT确实是一个比较大的创新,影响力大&…

Training-free regional prompting for diffusion transformers
通过语言模型来构建位置关系的,omnigen combine来做位置生成,其实可以通过大模型来做,不错。
1.introduction 文生图模型在准确处理具有复杂空间布局的提示时仍然面临挑战,1.通过自然语言准确描述特定的空间布局非常困难,特别是当对象数量增加或需要精确的位置控制时,2.…

【大模型系列篇】动手部署实践国产文生图模型-腾讯混元DiT
首个中英双语DiT架构,混元-DiT,高性能细粒度中文理解-多分辨率扩散Transformer模型。 腾讯提出的混元DiT,是一个基于Diffusion transformer的文本到图像生成模型,此模型具有中英文细粒度理解能力。为了构建混元DiT,精心…

xDIT 框架多GPU推理DIT PixArt扩散模型使用案例
参考: https://github.com/xdit-project/xDiT
安装 :
pip install xfuserxfuser 0.2
项目下载:
git clone https://github.com/xdit-project/xDiT.git代码运行
–model 指定模型;nproc_per_node gpu数量,另外pipefusion_parallel_degree与ulysses_degree 乘机要等于gpu…
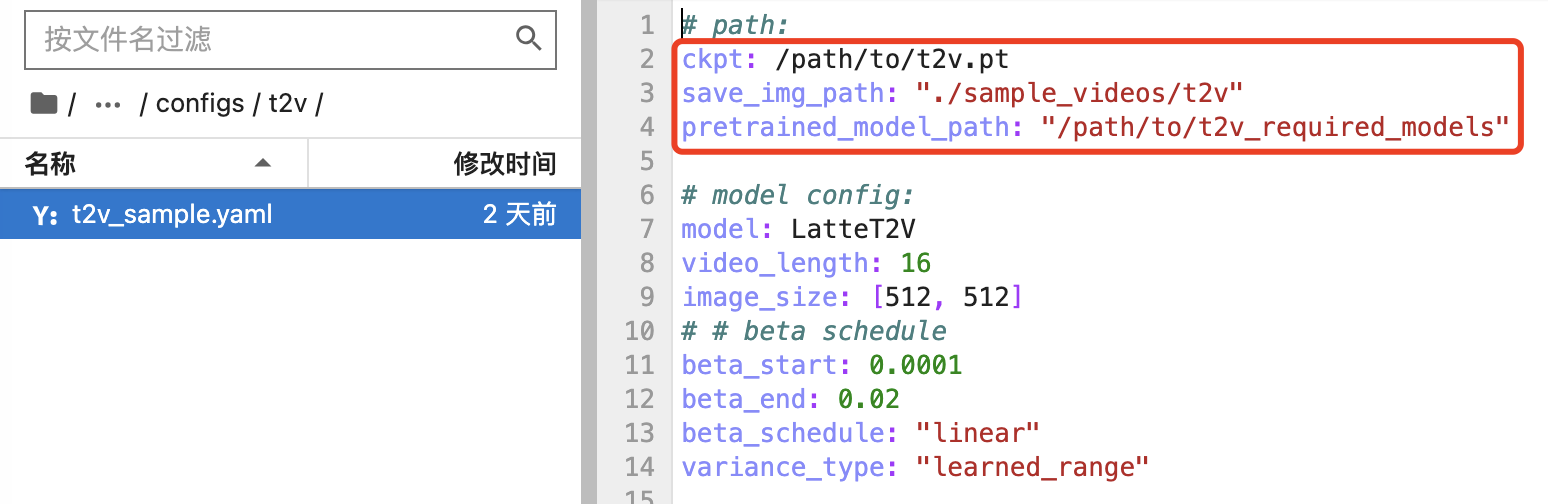
Latte:一个类似Sora的开源视频生成项目
前段时间OpenAI发布的Sora引起了巨大的轰动,最长可达1分钟的高清连贯视频生成能力秒杀了一众视频生成玩家。因为Sora没有公开发布,网上对Sora的解读翻来覆去就那么多,我也不想像复读机一样再重复一遍了。
本文给大家介绍一个类似Sora的视频生…
OpenAI视频生成模型Sora的全面解析:从ViViT、扩散Transformer到NaViT、VideoPoet
前言
真没想到,距离视频生成上一轮的集中爆发(详见《视频生成发展史:从Gen2、Emu Video到PixelDance、SVD、Pika 1.0、W.A.L.T》)才过去三个月,没想OpenAI一出手,该领域又直接变天了
自打2.16日OpenAI发布sora以来(其开发团队包…

多模态论文笔记——U-ViT
大家好,这里是好评笔记,公主号:Goodnote,专栏文章私信限时Free。本文详细介绍U-ViT的模型架构和实验细节,虽然没有后续的DiT在AIGC领域火爆,但为后来的研究奠定了基础,但其开创性的探索值得学习…